Ned i grøten - Snowflake Del 1: Mikropartisjoner
av Eivind Kleiven, Seniorkonsulent
Ned i grøten
Ned i grøten er en skriveriserie for deg som ønsker et lite innblikk i ulike teknologier. Vår første Ned i grøten handler om Snowflake og består av flere deler. Hver del handler om en egenskap/funksjon som Snowflake tilbyr, og vi begynner altså med Mikropartisjoner.
Hva er Snowflake?
Snowflake er en skybasert SaaS (Software-as-a-Service) dataplattform som støtter strukturerte, delvis-strukturerte og ustrukturerte data. Snowflake krever minimalt med konfigurasjon.
Snowflake skiller datalagring fra dataprosessering og kan behandle store datamengder raskt med fleksibel håndtering av skalering.
Tjenesten leveres i populære skyer som Azure, AWS og Google Cloud Platform.
Hva er mikropartisjoner?
I de fleste databasesystemer kan man angi hvordan data i en tabell skal partisjoneres. Da styrer en regel hvilken partisjon hver rad tilhører. For eksempel er det vanlig å lage en partisjon per måned der verdien i en datokolonne avgjør hvilken partisjon raden hører til. Det kan være en ganske komplisert og tidkrevende oppgave å velge gode partisjoner. I tillegg er det ofte slik at valgene som tas fungerer godt for et sett av spørringer, men kanskje ikke like godt for et annet sett av spørringer.
I Snowflake skjer partisjonering automatisk. All data i en tabell deles automatisk inn i mikropartisjoner som hver består av mellom 50 MB og 500 MB ukomprimerte data. Faktisk størrelse på disk er mindre siden Snowflake også komprimerer dataene, i tillegg krypteres dataene.
Hver mikropartisjon inneholder en gruppe med rader som lagres kolonnevis. For hver mikropartisjon lagrer Snowflake metadata om alle radene i partisjonen, som for eksempel antall distinkte verdier og spekteret av verdier for hver kolonne i partisjonen. Når Snowflake skal gjennomføre en spørring mot en tabell, så trenger den kun å skanne gjennom de kolonnene som spørringen refererer til, og ved hjelp av metdataene kan mikropartisjoner som ikke er relevant for spørringen ignoreres.
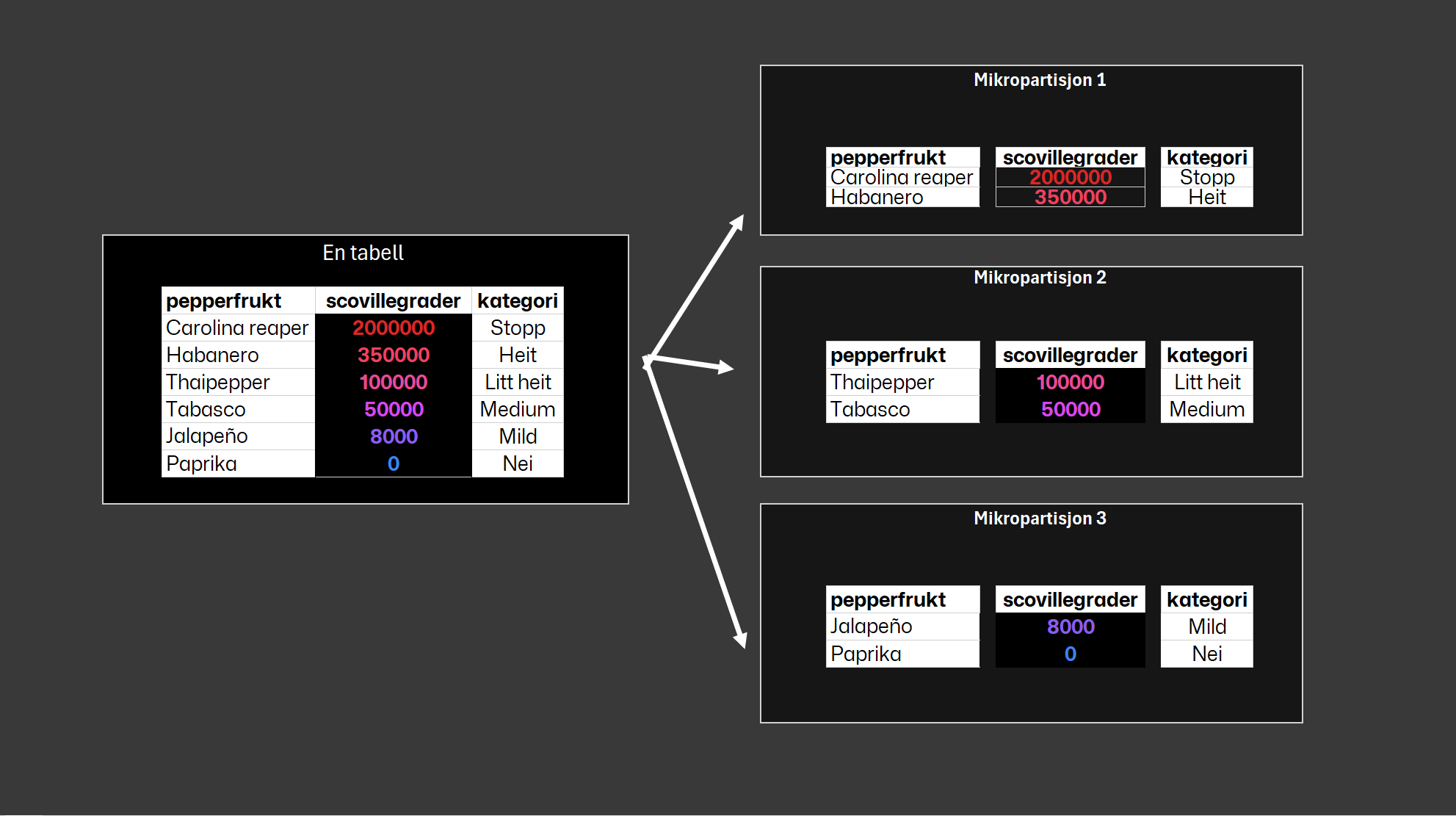
Hver kolonne i en mikropartisjon komprimeres individuelt, og Snowflake avgjør automatisk den beste komprimeringsalgoritmen for kolonnene i hver mikropartisjon. Dette er veldig gunstig særlig for tabeller med kolonner som inneholder få distinkte verdier. For eksempel i en tabell som har millioner av rader per dag der en kolonne inneholder datoen/dagen og en annen inneholder en faktaverdi, så vil nok komprimeringen være veldig effektiv på datokolonnen.
Mikropartisjoner er en viktig brikke i Snowflake sin arkitektur, og det er nyttig å kunne litt om det når man skal forstå andre egenskaper Snowflake har, som for eksempel Zero-Copy Cloning. Mer om det i del 2 av Ned i Grøten - Snowflake.